RAG Pipeline modeling
Recently, there has been a growing popularity among generative AI projects for systems that answer questions based on documents. Everyday, projects are being created that answer questions based on PDFs, videos, or any other source of information.
The popularity of these systems is understandable. There is a very low entry barrier to develop such a system and a very clear use case.
There are tons of documents and information — why search in the traditional way when you can ask a question and get what you’re really looking for. This system is called RAG (Retrieval Augmented Generation).

What is RAG?
There are a huge number of documents that are divided into small pieces, transformed into a vector representation, and then any user question (which is also transformed into a vector) returns the most similar (a simple cosinDistance function that calculates the similarity coefficient) pieces of documents, which in turn are sent to LLM (GPT, Anthropic etc.) for generating an answer.
And, I probably won’t be afraid to say that this is an incredibly simple and most useful use case of GenAI systems and capabilities right now.
Why simple? Because using LangChain or LlamaIndex you can do this in 2–3 lines of code. It will set up the vector base for you, cut the documents, and connect the model.
Due to such popularity, people have suddenly started noticing the limits and restrictions of such systems, especially when it comes to commercial products, where every inaccurate answer or hallucination seriously affects and carries reputational risks for the business.
In this article, I want to share some of the problems that have been discovered when working with RAG modeling and propose solutions to most of them.
Main problem with RAG.
Let’s start with the main problems that exist. The first time you set everything up, ask a question and get an answer — it seems like magic with limitless prospects.
But when we start digging deeper, we immediately find that there are a huge number of problems if we want to use this for commercial purposes.
Cost.
Traditionally, most of all the projects that are starting to appear now or have appeared in the last six months use several models — GPT-4, GPT-3.5, Anthropic. They have quite good quality, a very simple API interface, and all frameworks like LangChain and LlamaIndex work with them.
Using the API on a pay-per-call model is an interesting but complex task on large volumes. There is an internal struggle between quality and cost. Using GPT-4 constantly amazes you with how smart and fast this model is. And the more you use it, the clearer you understand how far competitors like Anthropic or the more “weak” GPT-3.5 are from this level.
And the quality issue is quite important if we are talking about working with a business that wants to give its customers quality answers, but also — not to give false ones. And the more we start using GPT-3.5 in the hope of reducing the amount of money spent — the more I am convinced that the quality is not what the business wants to get. Undoubtedly, there is a chasm in quality between GPT-4 and other models. But also, there is an abyss between the price for GPT-4 and others.
Let’s calculate. Suppose you have a regular RAG product. You have 10 companies, medium and large businesses. Each of them asks 100 questions a day (which is very little, considering the number of employees of medium and large businesses). That’s 1000 questions a day. The average number of tokens spent on generation is 8 thousand (5 thousand — prompt, 3 thousand — generation).
If we calculate everything, we get:
The cost per month for the prompt and completion tokens can be calculated as follows:
For the prompt: 5K tokens * $0.03/1K tokens * 1000 times per day * 30 days = $4,500
For the completion: 3K tokens * $0.06/1K tokens * 1000 times per day * 30 days = $5,400
So, the total cost per month would be $4,500 (prompt) + $5,400 (completion) = $9,900.
And the average cost of your service for them is $1000. At the end of the month, you have a “good” profit of $100. In the most pessimistic scenario, where the client asks 100 questions a day.
Now, let’s do the same exercise for GPT-3.5 and get a figure — $810.
And of course, in reality all the products that we see — they use GPT-3.5 as a model for working with client questions. But if we are talking about medium and large businesses — any hallucination can lead to the fact that they will simply terminate the contract with you and stop using you.
Hallucinations.
The next point, which is very important and problematic in general for all models — is hallucinations. That is, when the model starts to invent something from itself, distorting the facts of the real world.
If we are talking for an ordinary user — in general, this is not a problem so huge as to pay attention to it. If we are talking about it from the point of view of business use — this is an incredibly big problem, which can lead to serious consequences: reputational risks, customer complaints, loss of loyalty.
That is, the business wants to get “magic”, which will reduce the number of human resources for onboarding new employees, for customer support — instead it gets the risk of a lawsuit due to unreliable information, loss of customer loyalty and reputational losses.
Non-compliance with the contextual prompt.
System prompt — this, if to bring an analogy, custom instructions, which a couple of months ago were added in ChatGPT. That is, the rules that you want the model to follow. For example, to greet, to be friendly, to ask the city at the beginning of the dialogue and so on. What a couple of years ago was set up with complex logical chains — people now do using only text.
And again, it returns to the dilemma between the quality of models — GPT-4 usually follows the rules, GPT-3.5 follows periodically, Anthropic follows rarely.
No matter how many iterations of prompts, what restrictions you do not put — models are very non-deterministic and the probability that your rule will be ignored is undoubtedly there. Which again, for an ordinary user is not such a scary situation, as for a business — this is an important condition that they want to have and be able to work with it.
These 3 key problems in most cases — are not solved by the standard change of the prompt. This is more of an engineering task, a task of modeling the flow in such a way as to make it not so expensive, but at the same time check for compliance with all rules and hallucinations.
Processing inside the flow.
In light of the issues mentioned above, there are some solutions that can partially help to minimize the impact of these factors on the quality and experience of using AI models, particularly RAG modeling in your business.
Smart Cache.
This topic is gaining popularity with the development of GenAI. There are already some projects that allow you to integrate a cache into your system.
I don’t particularly like these approaches:
1) They don’t solve the main problem of optimizing costs with questions that have the same intent.
2) The business user has no interface for controlling and working with the cache.
Therefore, I want to offer my view on solving this problem.
If we talk about using GenAI in customer support or onboarding new employees, we come to the conclusion that about 65–70% of questions from customers/employees have the same intent. That is, when a customer asks:
“What is your address?” and “How do I get to you?” — these are different questions, but they have the same intent. The answer to one question can be considered the answer to another question. And the key task of the smart cache is to recognize the intent and give an answer that already exists, instead of going and generating it again.
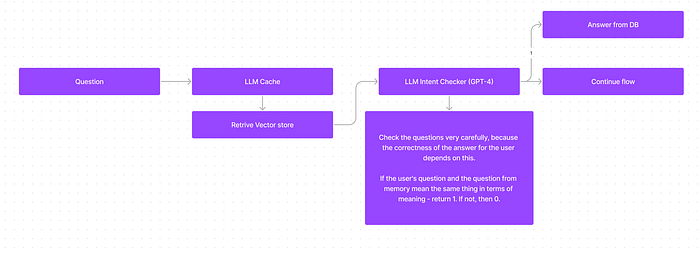
By using a smart cache at the first step, you reduce the amount of money you will spend on LLM calls and, most importantly, the answer will be correct and of high quality.
And at the same time, if you give business users the ability to determine correct and incorrect questions, give them the ability to save them — this, in the long run, can make your product incredibly fast, useful and the whole business will have confidence that this is something they can trust.
Validation and Rule Application.
The problem of hallucinations and rule application is one of the key ones we have already discussed.
And the solution I want to propose is quite non-trivial. Namely, a two-stage response system. This means that instead of calling a model where there is context and user rules once and then generating a response — we run it twice with a slightly changed prompt for the system.
And the purpose of this second time is to give the model such instructions that will direct all its attention to checking its answer and applying all the rules that the user has set.
This system is not perfect. We are currently actively conducting experiments, and in the next posts, I will try to share the results of our experiments.
And at the same time, the two-stage system does not make waiting for a response very long. Everything happens within 6–8 seconds, where the person waits for 6 seconds, and the streaming and response begin in the next 2 seconds.
We recommend doing this with the GPT-3.5 model, as in terms of cost and waiting time — this is the best option.
Conclusions.
All the problems listed are fundamental and the smartest people are working on solving them.
Some say these are fundamental problems with the current design of models and they need to be fundamentally adjusted during training for this, others solve it by creating additional steps, creating work models.
I agree with the first option, that of course, if the model is trained to look at the context and answer questions based on it, and it has some additional attention mechanisms that help reduce defects, hallucinations, and inaccuracies — this will greatly help improve the quality of work. But despite my agreement with the first option, I am very interested in dealing with the second one. Building models that help maintain a balance between quality and cost is incredibly interesting and valuable for business and the community.

